
![]()
CoreML対応の軽量版、オフライン、話者分離・長時間対応文字起こしアプリ「FFTrans Neu」ですが、バージョンアップして1.4.0をリリースいたしました。
1.4.0で追加した内容は以下の通りです。
[ Version 1.4.0 ]
・Segment Timeline Adjustmentを搭載し、タイムライン精度を向上
・タイムライン編集用の波形表示調整ホバー機能を追加
・文字起こし完了直後の本文の表示が一部隠れることがある問題を修正
・音声抽出処理のタイミングを変更
・ハルシネーションフィルターを強化
今回は主にタイムラインの精度を磨く部分に注力してみました。
FFTrans Proと比べてCoreML版ではやはり話者分離やVADの部分の精度が劣る傾向がありました。
FFTrans-DSRを実現するための別ベクトルのEmbeddingが現状では用意できないことと、モデルの精度はやはり差が出てしまいます。
話者の精度は現状すぐには解決できませんので、今回はタイムラインの精度を少しでも良くしようという取り組みです。
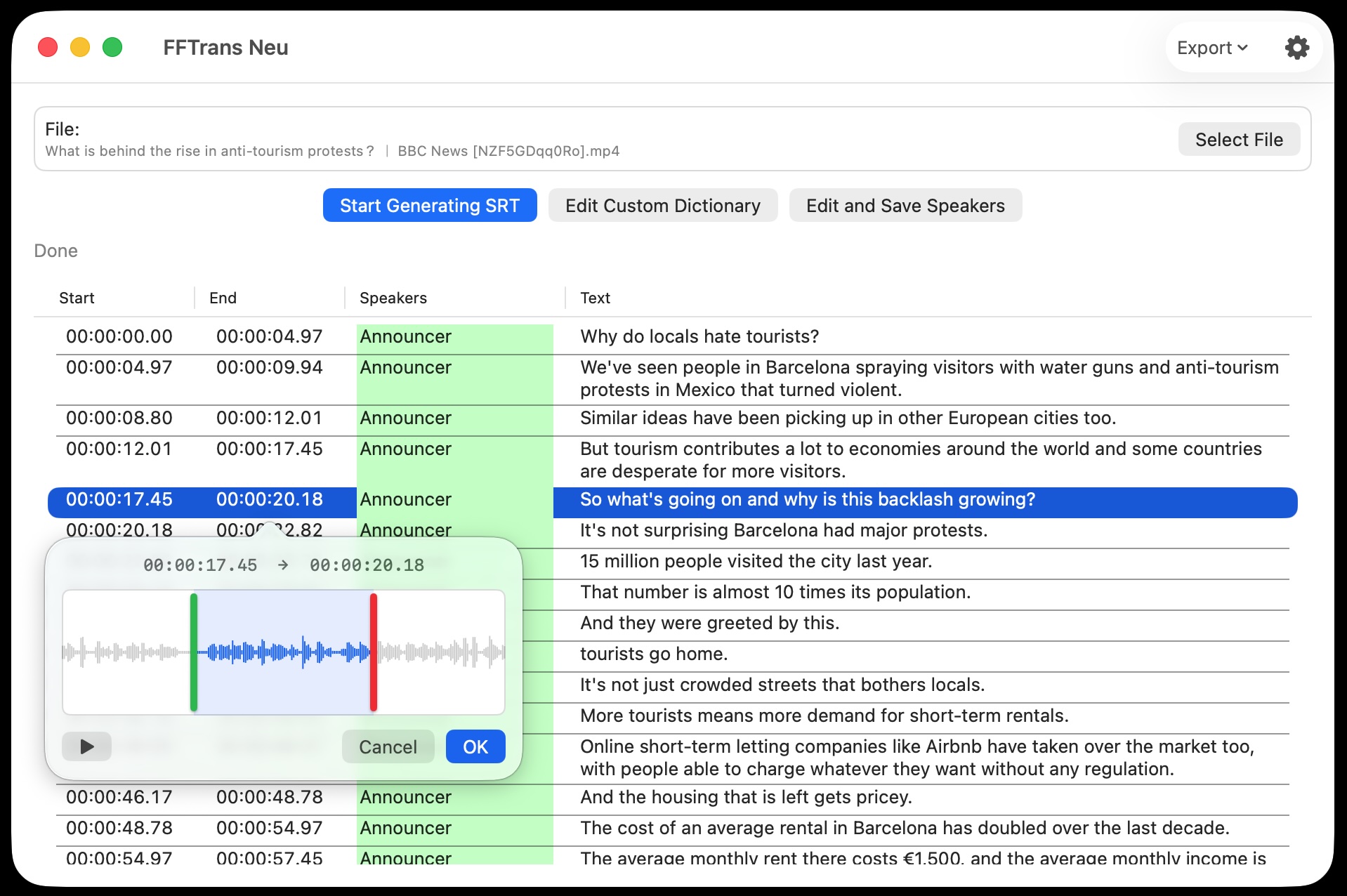
まずは「Segment Timeline Adjustment」という、以前から温めていた機能を実装しました。
話者分離されたタイムラインの誤差を文字起こしのSegment情報をもとに補正するものです。
とはいえ、Word Timestampsを使うと文字起こし自体の速度が低下してしまいますので、処理速度はほとんど変えずにズレが大きい部分を補完する形です。
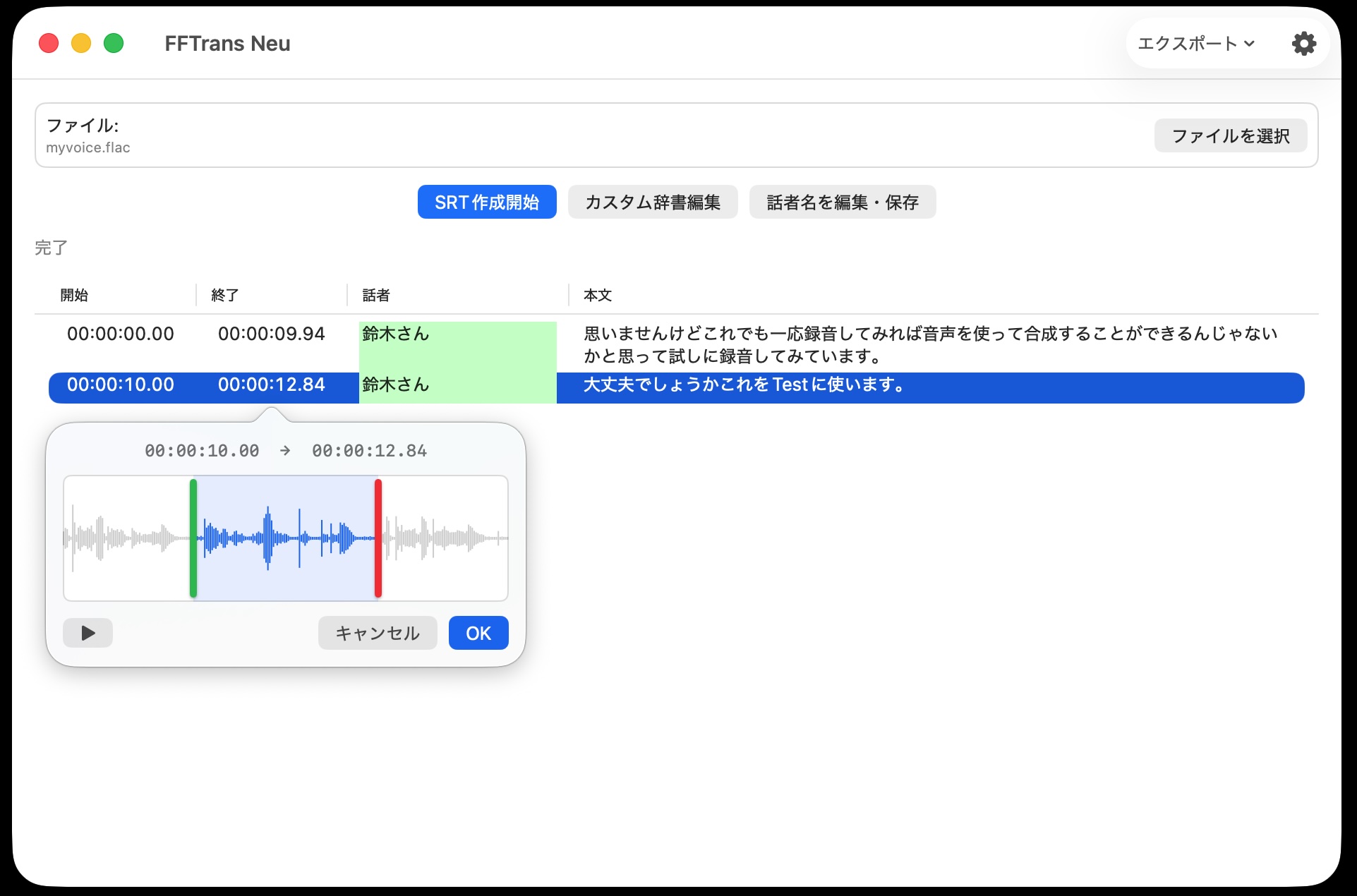
そして文字起こし後の編集作業の効率化も図るべく、波形表示調整ホバー機能を追加しました。
他の文字起こしアプリでも波形表示しているものを結構見かけますが、全体の波形を表示しても正直あまり意味がないと思っています。
今回の機能では各タイムラインの開始・終了時間をクリックすると、その範囲の前後2秒を含む波形を表示し、そこで範囲選択してもらう形としています。
もちろん、選択範囲の音声を聞くこともできます。
なお、これは以前から搭載していますが、前行の終了時間と次行の開始時間が同一の場合は、一方を修正すると自動的にもう一方も連動して修正されるようになっています。
連続した発話を句読点などで区切って字幕にする場合にはかなり効率化が図れるはずです。
また文字起こし精度も量子化やVADのズレに伴ってハルシネーションが文の途中や末尾に混入することがあったので、ハルシネーションフィルタも強化しました。
単純にNGワードで弾く形ではなく、文字長や言語ごとの話速を条件にしているのは以前と同様で、それを強化した形です。
正直、モデルそのものの性能差はまだあるものの、FFTrans Proよりも機能面は充実してきた状態です。
ProはPySideベースなので、どうしてもUIには限界がありますからね。
なお、現在はFFTrans Neuと並行して、リアルタイム文字起こし系の「FFTrans HUD」も絶賛開発中です。
ますます充実を図っていくFFTransシリーズを今後ともよろしくお願い申し上げます。