
Coqui TTSを用いたボイスクローニングをPythonで構築してみました。
せっかくなのでPyQtとpyinsallerでアプリ化もしましたが、若干問題もあってそこも書いておこうと思います。
まずはCoqui TTSがPythonから使える環境構築ですが、Python 3.10系が望ましいです。
モジュールの互換性は相変わらず結構厳しく、TTS[ja]が0.22.0、numpyは1.24.0としました。
マルチランゲージモデルではtransformersも4.38.0にする必要がありました。
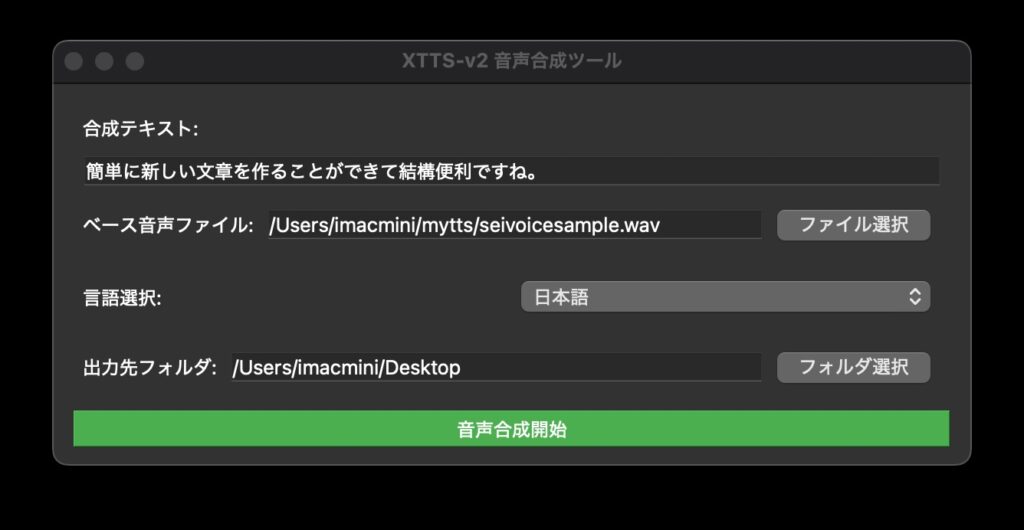
なお、クローニング対応モデルは「tts_models/multilingual/multi-dataset/xtts_v2」をチョイスしました。
コマンドラインのTTS実行はわりと簡単に動くのですけど、Pythonから使うとなると特に厄介ですね。
ちなみにコマンドラインだとこんな感じでクローニング元となる音声を参考に音声合成できます。
tts –model_name tts_models/multilingual/multi-dataset/xtts_v2 \
–language_idx ja \
–text “ここに合成したいテキストを入力します。” \
–speaker_wav ./voicesample.wav \
–out_path ./output_cloned_voice.wav
サンプルボイスは10秒くらいでも大丈夫らしいですが念のため2分くらい用意しました。
背景ノイズがあったりすると精度が下がるので、RNNoiseやDemucsで声のみにしておくと良いでしょう。
Pythonからの呼び出しは実はそこまでややこしいということはなく、Coqui TTSのバージョンで言語指定のオプション名が異なる(?)ところに引っかかっただけでした。
tts.tts_to_file(
text=TEXT,
speaker_wav=REFERENCE_AUDIO,
file_path=”output_py.wav”,
language=”ja”
)
合成の質感は流暢とまではいきませんが、十分使えるレベルです。
また参考にした音声が日本語でもクローニングする音声は英語やフランス語等にすることが可能です。
もちろん滑らかさや自然さの点では同じ言語にしたほうが良いでしょうけど、そんなに違和感なく他言語で喋らせることができます。
[ 日本語合成例 ]
[ 英語合成例 ]
依存関係が複雑なのであとで動かなくなったら嫌だなと思い、pyinstallerでいつものようにアプリにしましたが、これが意外と手こずりました。
パッケージに入れるファイルはTTS、trainer、gruutのVERSIONファイル、jamo、unidic(liteを使っているならそちらを指定)、あとはcutletのexceptions.tsvなどが必要です。
中でpyコードも実行されちゃうようなので、TTS、trainer、inflect、typeguard、gruutのファイルも入れ込む必要があります。
そして起動時にはかなり待たされることになりまして、どうやらXprotectServiceが動作して妨げられるようです。
なぜかOnedirを指定してもOnefileで生成されるのが原因かなと思いましたが、単純に挙動があやしいのでしょうね。
解決策としてはコード署名をアプリに付けるくらいしかないみたいです。
アプリとしての使い勝手はあまり良くありませんが、これで動作する環境を封じ込められるのはまあ良いでしょう。
リアルタイム翻訳時に自分の声で喋らせるといった用途にはまだ速度の問題がありますけど、わりと使える(使えるところまで持っていけばですけど)機能かなと思います。