
Tesseract.jsを用いてWebブラウザでのOCRをオフラインで実行できる形で実装してみました。
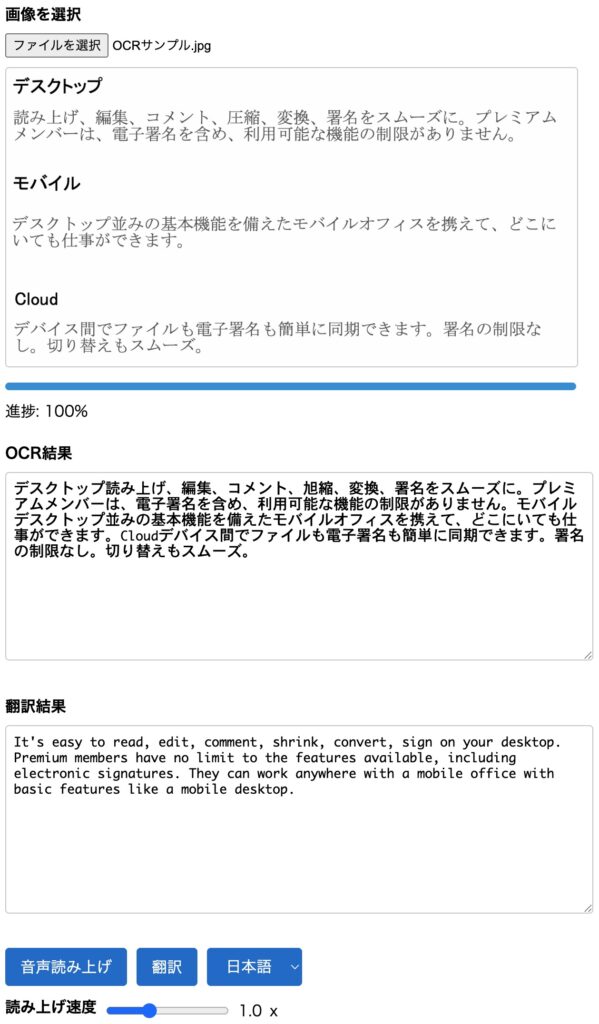
日本語と英語に対応し、ついでにOCRした文章の読み上げと翻訳もオフラインでできるようにしました。
日本語でもスペースをやたらと挟んでくるのでそこはOCR後にほどほどに修正をかけています。
読み上げはWeb Speech API(オフラインでも動作する)、翻訳はTransformers.jsでXenova/nllb-200-distilled-600Mを用いました。
いずれも完璧とはいきませんが、Webブラウザ上で外部のクラウドを使わずにできるのはそれなりにメリットがあるかと。

ちなみに日本語の縦書きにも対応可能ですが、その場合は縦書き指定をする必要があります。
そもそも今はmacOSやiPhoneでも画像の文字列が切り出せる時代ではありますけどね。